This study aims to employ machine learning (ML) tools to cluster patients hospitalized for acute exacerbations of chronic obstructive pulmonary disease (COPD) based on their diverse social and clinical characteristics. This clustering is intended to facilitate the subsequent analysis of differences in clinical outcomes.
MethodsWe analysed a cohort of patients with severe COPD from two Pulmonary Departments in north-western Spain using the k-prototypes algorithm, incorporating demographic, clinical, and social data. The resulting clusters were correlated with metrics such as readmissions, mortality, and place of death. Additionally, we developed an intelligent clinical decision support system (ICDSS) using a supervised ML model (Random Forest) to assign new patients to these clusters based on a reduced set of variables.
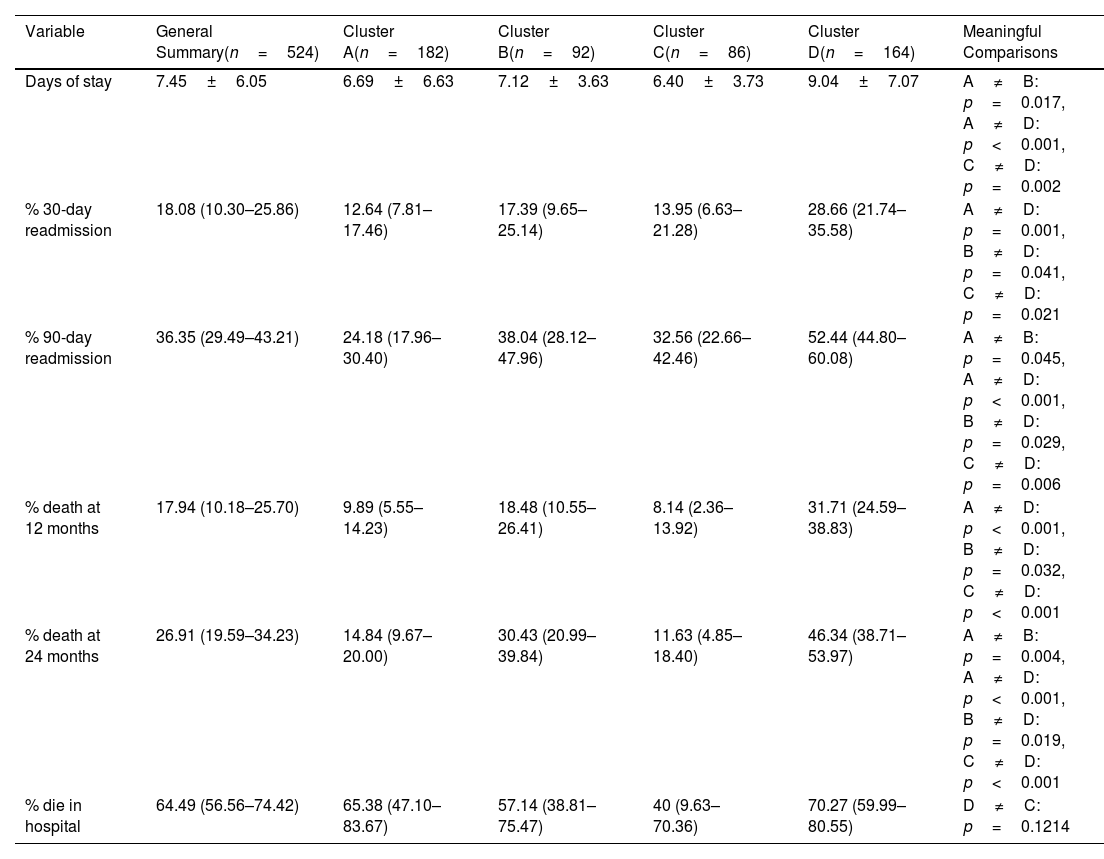
ResultsThe cohort consisted of 524 patients, with an average age of 70.30±9.35 years, 77.67% male, and an average FEV1 of 44.43±15.4. Four distinct clusters (A–D) were identified with varying clinical–demographic and social profiles. Cluster D showed the highest levels of dependency, social isolation, and increased rates of readmissions and mortality. Cluster B was characterized by prevalent cardiovascular comorbidities. Cluster C included a younger demographic, with a higher proportion of women and significant psychosocial challenges. The ICDSS, using five key variables, achieved areas under the ROC curve of at least 0.91.
ConclusionsML tools effectively facilitate the social and clinical clustering of patients with severe COPD, closely related to resource utilization and prognostic profiles. The ICDSS enhances the ability to characterize new patients in clinical settings.